Natural Language Processing
Bridging computers and human languages
What is Natural Language Processing?
Natural Language Processing, or NLP, is a field derived from artificial intelligence, computer science, and computational linguistics that focuses on the interactions between human (natural) languages and computers. The main goal of NLP is to program computers to successfully process and analyze linguistic data, whether written or spoken.
Operations in the field of NLP can prove to be extremely challenging due to the intricacies of human languages, but when perfected, NLP can accomplish amazing tasks with better-than-human accuracy. These include translating text from one language to another, speech recognition, and text categorization.
Due to varying speech patterns, accents, and idioms of any given language; many clear challenges come into play with NLP such as speech recognition, natural language understanding, and natural language generation.
What Can NLP accomplish?
The following applications are driven from the use of NLP:
- Spelling / grammar accuracy check, as used in word processing software such as Microsoft Word and Grammarly
- Speech recognition, which provides a way for computers to understand spoken instructions.
- Smart search-engine predictions as used in Google and Amazon web store
- Messenger bots and interactive voice response used for hands-free customer support
- Digital assistants, such as Google Assistant, Alexa, and Siri.
NLP Challenges
While extremely powerful, NLP models can also be difficult to build because of the dynamic and nuanced nature of human languages. Some of these challenges include:
- Human language is extremely dynamic. The meaning of words changes subtly over time, and new words are constantly introduced into use. This means that NLP models must follow word trends, and understand how those tie into concepts and messages.
- Human lanugage is nuanced. The complex characteristics of human languages such as sarcasm and suffixes cause problems for NLP. High level emotive constructs, like sarcasm, are subtle and abstract for a machine to pick up on. Low-leve problems like suffixes can be a bit easier for a machine to decipher, but still present difficulties as the machine may confuse variations of one word with contractions or endings of another.
Even with these challenges, there are many powerful computer algorithms that can be used to extract and structure from text.
How does NLP work?
NLP works through the inclusion of many different techniques, from machine learning methods to rules-based algorithmic approaches. A broad array of tasks are needed because the text and language data varies greatly, as do the practical applications that are being developed. Consider a chatbot or digital voice assistant as an example.
To make sense of a request, the computer needs to:
- receive the data in a format it can understand
- recognize individual words and parse them for an "intent" or action
- convert the intent to a task it understands how to do
- execute the task
- take the results and communicate those in a way that the person will understand
The very best NLP systems go further, and learn from interactions. A chatbot might learn how to converse on new topics as part of its interaction with people, for example.
At a technical level, NLP tasks break down language into short, machine-readable pieces to try and understand relationships between words and determine how each piece comes together to create meaning. A large, labeled database is used for analysis in the machine's thought process to find out what message the input sentence is trying to convey. The database serves as the computer's dictionary to identify specific context.
Parsing Text
NLP makes use of several algorithmic techniques to parse text. These include: lexical analysis and synctactic analysis.
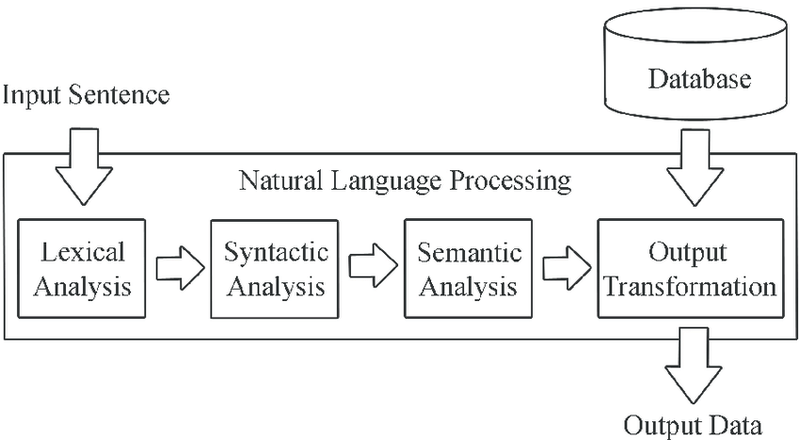
Lexical Analysis
Lexical analysis is the process of trying to understand what words mean, intuit their context, and note the relationship of one word to others. It is often the entry point to many NLP data pipelines. Lexical analysis can come in many forms and varieties. It is used as the first step of a compiler, for example, and takes a source code file and breaks down the lines of code to a series of "tokens", removing any whitespace or comments. In other types of analysis, lexical analysis might preserve multiple words together as an "n-gram" (or a sequence of items).
After tokenization, the computer will proceed to look up words in a dictionary and attempt to extract their meanings. For a compiler, this would involve finding keywords and associating operations or variables with the toekns. In other contexts, such as a chat bot, the lookup may involve using a database to match intent. As noted above, there are often multiple meanings for a specific word, which means that the computer has to decide what meaning the word has in relation to the sentence in which it is used.
This second task if often accomplished by associating each word in the dictionary with the context of the target word. For example, the word "baseball field" may be tagged in the machine as LOCATION for syntactic analysis (see below).
Syntactic Analysis
The syntax of the input string refers to the arrangement of words in a sentence so they grammatically make sense. NLP uses syntactic analysis to asses whether or not the natural language aligns with grammatical or other logical rules.
To apply these grammar rules, a collection of algorithms is utilized to describe words and derive meaning from them. Syntax techniques that are frequently used in NLP include the following:
- Lemmatization / Stemming - reduces word complexity to simpler forms that have less variation. Lemmatization uses a dictionary to reduce the natural language to its root words. Stemming uses simple matching patterns to strip away suffixes such as 's' and 'ing'.
- Parsing - This is the process of undergoing grammatical analysis of a given sentence. A common method is called Dependency Parsing, which assesses the relationships between words in a sentence.
- Word Segmentation - This is the separation of continuous text into separate words. In English this is easy because all words are usually separated by spaces, but for some languages like Japanese and Chinese they do not mark spaces for words. This is when word segmentation becomes very useful.
Semantic Analysis
Semantics refers to the meaning that is conveyed by the input text. This analysis is one of the difficult tasks involved in NLP, as it requires algorithms to understand the meaning and interpretation of words in addition to the overall structure of a sentence. Semantic analysis techniques include:
- Entity Extraction - This means identifying and extracting categorical entities such as people, places, companies, or things. It is essential to simplifying the contextual analysis of natural language.
- Machine Translation - This is used to automatically translate text from one human language to another.
- Natural Language Generation - This is the process of converting information of the computer semantic intention into readable human language. This is utilized by chatbots to effectively and realistically respond to users.
- Natural Language Understanding - This involves converting pieces of text into representations that are structured logically for the computer programs to easily manipulate.
Example NLU Model: Chatbot
Natural Language Understanding often uses configurations to inform the machine learning model about what types of actions a program should take. These configurations include information about "intents", and facilitate matching input data to the actions. The YAML manifest in the code listing shows how these manifests look. It is written for the RasaNLU framework, a popular open source framework for building chatbots.
The manifest tells Rasa about three intents: Say hello, get a list of restaurants, say goodbye, and the types of language which should prompt that action. Rasa also provides examples of text that might correspond to variables of interest. For example, when saying hello it is able to parse out names. When asking about restaurants, it attempts to parse out types of cuisine such as Sushi
The example in the listing is taken taken from "NLP for Hackers." The link includes additional examples as well as a tutorial on how to build a complete chatbot on top of the Rasa framework.
language: "en" pipeline: "spacy_sklearn" data: | ## intent:greetings - Hello there! My name is [John](person)! - Hi there! - Hi, I m [Nate](person) - Hi - How are you? - hi there, this is [Eliza](person) ## intent:get_restaurants - what are some good restaurants around? - Are there any good [sushi](cuisine) places around? - Can you show me some interesting [burger](cuisine) places nearby - show me some [chinese](cuisine) places nearby - i want a [chinese](cuisine) restaurant nearby - I m in the mood for some [mediteranean](cuisine) food - Want to try out a [vegan](cuisine) restaurant please ## intent:bye - thanks, bye - great, bbye - see you - bye - good bye - awesome, see you later - goodbye
Looking forward
Natural Language Processing is an incredibly powerful tool that is critical in supporting machine-to-human interactions. Although the technology is still evolving at a rapid pace, it has made incredible breakthroughs and enabled wide varieties of new human computer interfaces. As machine learning techniques become more sophisticated, the pace of innovation is only expected to accelerate.
Comments
Loading
No results found