DevOps: Engineering the Software Lifecycle
DevOps is an approach to developing, testing, and deploying software. It is, in effect, the convergence of everything.
Software, in the words of Marc Andreesen, is "Eating the world." It touches every industry, powers more processes than ever before, and impacts nearly every aspect of business.
The improvements we have made in its development and deployment are a big reason as to why it has become so powerful. At a constant rate, new technologies and approaches to build more and robust scalable things emerge, become adopted, and are discarded as new strategies take their place. As predicted by Gordon Moore in 1965, computers have continued to double their computing power every year and a half; and since the Second World War when Alan Turing's bombe was used to break the codes of Germany's Engima machine, the makers of software have sought better ways to build systems.
We adopt new computing paradigms, such as virtualization and cloud. We learn important lessons of what works, what doesn't, and that which doesn't work as well as expected. One step at a time, one project at a time, the state of the art advances. Looking at the miracles of the modern world, it's clear that technology advances; and along with it we make advances in the techniques we use to build technology.
DevOps is a set of practices and tools to build better software. It combines development and operations teams into a whole (dev + ops = DevOps), and encourages them to work together. The unified team is then expected to own their application: from planning and coding, to testing, deployment, operations, and emergency. When something goes wrong, the developer who wrote the feature will often work alongside the QA engineer and systems administrator to troubleshoot and bring the service back online. Amazon, one of the early pioneers of DevOps practices and procedures, summarizes the whole of "What is DevOps" succinctly:
DevOps is the combination of tools, practices, and philosophies that increases an organization's ability to deliver applications and services at high velocity ... This allows for products to evolve and improve at a faster pace than organizations using traditional software development and management processes. Improved speed enables better customer service and enhances the ability to compete more effectively in the market.
It is, in effect, the convergence of everything: philosophy, practice, and architecture; and its proponents claim that it is revolutionary, capable of changing everything. But is it really? What are the benefits of DevOps? Are they worth the investment they require and the disruption they cause? What are the parts and pieces? How do they work together, and how can you start to take advantage of DevOps practices? In this article, we look at a number of these questions and attempt to look past the hype to some of the practical benefits of DevOps.
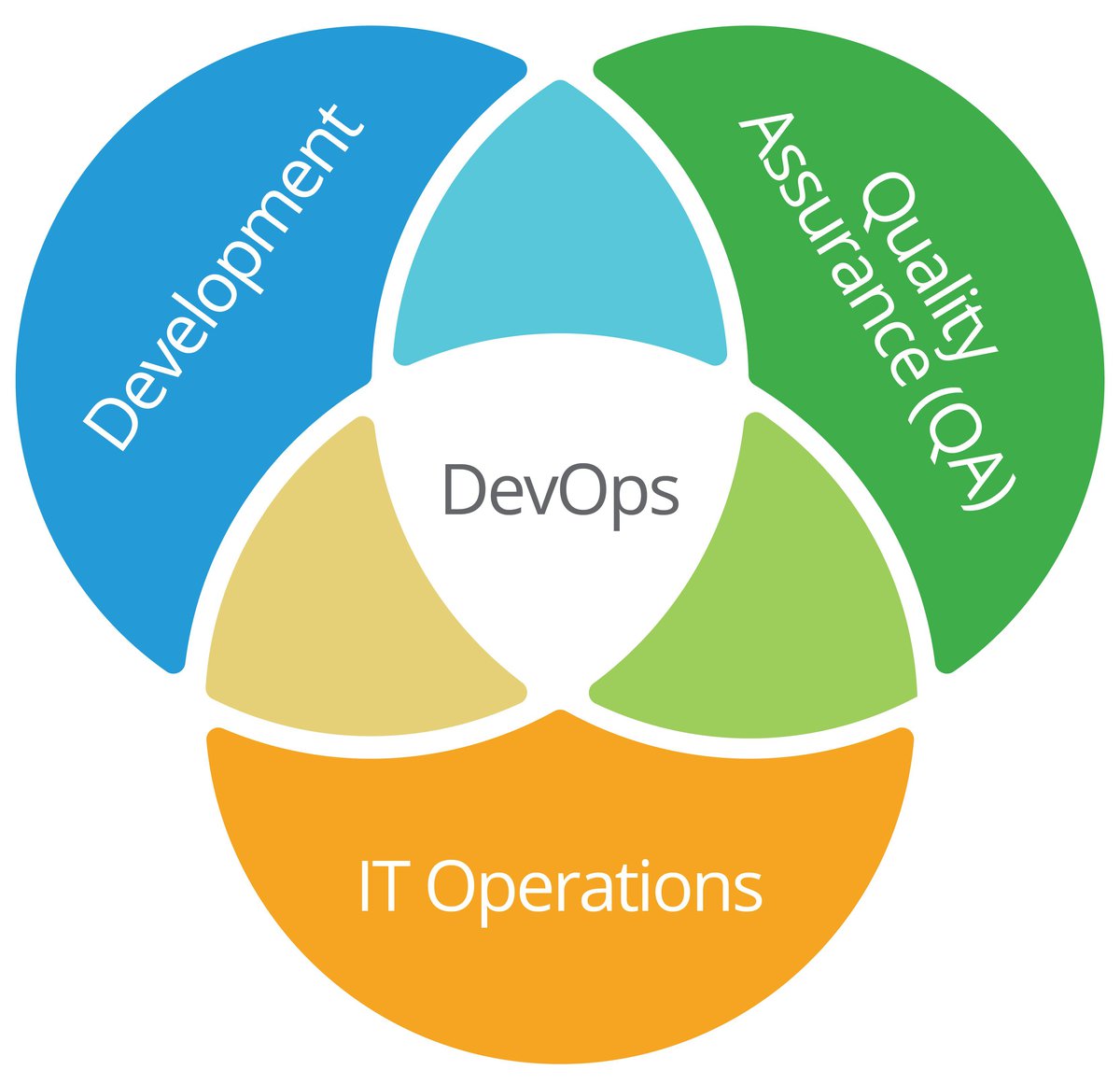
Benefits of DevOps
Perhaps a good place to start in this whirlwind tour is a discussion of the benefits. The DevOps movement started to coalesce between 2003 and 2008 (depending on who you ask) at large companies like Amazon, Google, Microsoft, and Netflix. At the time, there had been a number of high profile software project failures (remember Windows Vista, four years late and billions over budget), and there was a widespread belief that traditional software development methods were not working.
Through many conversations (both amongst themselves and with management), a set of best practices started to emerge that could improve the process by which software was built. Developers implemented some of those ideas into tooling, and operations enthusiastically adopted those tools to make their jobs easier. Over time, the practices and utilization of associated tools percolated up the management chains in many companies where they became adopted as formal policies. From the bottom-up, then, many companies find out that they are already practicing DevOps because that's how their technical staff want to do things.
Companies that include DevOps in the life cycles of their applications can expect a myriad of benefits. It's worth noting that (despite the hype), DevOps has been around for quite some time. There is now some fifteen years of data to help describe its benefits. Some of those benefits include: Sixty-three percent of organizations polled using DevOps have seen increased software releases. In 2013, DevOps teams were able to spend thirty-three percent more time on infrastructure improvements, having saved time in other areas. Teams using DevOps even work fewer hours outside of normal work hours.
Other major benefits of DevOps come in the ability to deliver applications, patches, and releases at a faster rate. Many companies that adopt practices such as continuous integration and delivery (CICD), have often been able to move from monthly or bi-monthly releases to daily product releases, and push fixes to customers in the span of a few hours. Additionally, they are more efficient and effective:
High performing organizations spend twenty-two percent less time on unplanned work and rework. They are able to spend twenty-nine percent more time on new work, such as new features and code.
DORA Metrics
DORA (DevOps Research and Assessment) is a research group that studies what enables high-performing software delivery organizations. Its work has identified four metrics that reliably capture both delivery speed and operational stability.
Change lead time: the time it takes for a code commit or change to be successfully deployed to production.
Deployment frequency: how often application changes are deployed to production.
Change fail rate: the percentage of deployments that cause failures in production, requiring hotfixes or rollbacks.
Failed deployment recovery time: the time it takes to recover from a failed deployment.
These DORA metrics matter because they show whether teams can deliver changes quickly without sacrificing reliability. High performers improve all four simultaneously demonstrating that speed and stability are not trade-offs, but rather outcomes of a well-designed delivery system.
From Experiment to Industry Standard
In 2017, when the first draft of this article was written, DevOps was already proving itself in the field, but enterprise wide adoption was still early. Surveys at the time commonly showed only seventeen percent of tech developers reported company-wide adoption of DevOps practices. That gap mattered, many teams were practicing "DevOps in pockets," while most enterprises were still working through cultural change, skills, and leadership alignment.
As we enter 2026, DevOps has moved from "disruptive" to the mainstream operating model of software development. It is no longer a niche practice limited to top-tier tech companies; it's the default expectation for how modern teams ship and run software. The Continuous Delivery Foundation's State of CI/CD report found 83% of developers report being involved in DevOps related activities, a strong signal that DevOps is no longer "Someone else's job." At the same time, a shared standardized language for the industry (lead by the DevOps Research and Assessment program or DORA within Google Cloud) to help understand progress and how DevOps has contributed to team performance.
What the Adoption of DevOps Has Accomplished
Over the last decade, DevOps has established a repeatable pattern for turning software delivery into a reliable system that can improve speed and operational performance when applied consistently.
- It made software delivery measurable and improvable. DevOps helped shift teams from "we feel faster" to "we can prove it." Using outcome-based measures like throughput and stability (deployment frequency, lead time, change failure rate, and time to restore). Those metrics are now a common foundation for performance discussions across engineering and leadership.
- It reduced the cost of change through automation and standardization. CI/CD, IaC, and automated testing moved delivery from artisanal, high-risk deployments to repeatable pipelines that can be validated continuously. This is the core reason DevOps scales: it converts tribal knowledge into systems and defaults. This is also why DevOps and cloud-native adoption have accelerated together.
- It improved operational resilience by tightening feedback loops. DevOps normalized the idea that engineering teams don't "throw code over the wall." They own reliability, recovery, and continuous improvement. That ownership loop (build → deploy → observe → learn) is what transformed operations from a separate function into a shared responsibility model.
- It expanded the scope of "delivery" beyond shipping code. Modern DevOps isn't about application deployments. It is also about providing platforms, tooling, security controls, and developer experience as reliable services that the organization can leverage. DORA's recent work around platform engineering is a major theme in how organizations need to evolve in order to provide mature, reliable, and consistent delivery of digital services.
Elite versus Low Performers
Data from DORA 2024 shows that high-performing DevOps organizations operate from a different footing and demonstrates that elite teams more effectively manage change, recover from failure, and sustain reliable delivery.
When compared to lower performers, elite performers realize

Where DevOps Still Needs to Go (as of 2026)
DevOps has succeeded as a delivery model, but success brings new challenges. The focus now is ensuring that velocity scales without fragility and automation strengthens governance instead of bypassing it. These remaining challenges emerge at the same fault line, where rapid changes meets the need for operational trust.
- Operational transparency has become non-negotiable. In a distributed system, you can't operate what you can't see, and many of the systems deployed into DevOps platforms remain opaque. The industry has started to tackle the challenges and create standardized instrumentation and telemetry pipelines (traces, metrics, and logs; with OpenTelementry emerging as a common standard), but much work remains. in the near future, default instrumentation, SLOs, tracing-first incident response, and telemetry driven release gates should become more integrated into release decisions.
- Supply-chain security is part of deployment and delivery. As organizations have automated build, test, and release processes with continuous integration and deployment; DevOps pipelines have become an attack surface. They sit at a point where code is transformed to software and are central to the process of creating trust before deployment. Incidents such as the SolarWinds supply-chain attack in 2020 demonstrated how build and release systems could be subverted to distribute malicious code. For that reason, security and validation is now a central tenant of DevOps. SBOMS are a mainstream expectation for ensuring transparency and risk management and guidelines such as SLSA have been created to ensure build integrity and reduce tampering. In the near-future, signed artifacts, provenance, dependency controls, policy-as-code, vulnerability management integrated into CI, and automated release approvals will become the expectation.
- Platform engineering and developer experience become the scaling lever. The bottleneck in 2026 isn't "can we automate," it's can we make the right thing the easy thing. Internal platforms reduce cognitive load, increase consistency, and keep teams from reinventing delivery mechanics. In practice, golden paths, self-service environments, standardized service templates, and opinionated defaults for security, logging, tracing, and deployment become increasingly important to allow for integration within an organization's systems. Platform engineering has become so important that it is being incorporated into DORA's formal metrics.
- AI-assisted delivery needs guardrails so speed doesn't create instability. AI tools have been widely adopted, but research is increasingly consistent on the risk: AI accelerates throughput while also increasing instability if teams don't adapt their review, testing strategy, change management, and operational feedback. DORA's AI-assisted research emphasizes that AI tends to amplify existing strengths and weaknesses, rather than magically fixing underlying delivery problems. Going forward, AI-assisted coding paired with stronger automated tests, policy checks, code review discipline, and post-deployment observability is needed.
AI On the Horizon
Research in the DORA 2025 report shows that successful AI adoption is less about advanced models and more about operational fundamentals. Organizations that benefit from AI consistently have strong DevOps foundations in place—clear organizational direction on AI use, the ability to work in small batches, healthy and accessible data, reliable internal platforms, disciplined version control, and infrastructure managed as code. In practice, DevOps platforms and habits are not optional for AI-driven success; they are the enabling conditions that allow AI to amplify productivity rather than instability.
Impact of AI on Software Development
Estimated effect of AI adoption on key outcomes, with 89% credible intervals. The data shows that AI can improve performance while also increasing instability, burnout, and development friction if underlying practices are weak. DORA 2025 Report.

(Re)Adopting a DevOps Mindset
Adopting DevOps is not simply a tooling decision — it requires an organizational commitment to shared ownership, disciplined practices, and continuous improvement. As DevOps has moved from early experimentation to an industry standard, successful organizations have learned that structure, incentives, and accountability matter as much as automation. The question is no longer whether to adopt DevOps, but how to apply its principles deliberately—strengthening the foundations that allow teams to move faster without sacrificing reliability, trust, or control. With that in mind, what are the goals of a DevOps organization, and what outcomes should it be designed to achieve?
Goals of a DevOps Organization (in 2026)
The goals of a DevOps organization reflect more than performance targets — they describe the conditions required for sustainable delivery. As DevOps has matured, these goals have become clearer and more disciplined, emphasizing practices that make speed repeatable, scale manageable, and change trustworthy. Effective DevOps organizations reinforce the fundamentals that keep delivery reliable, especially as AI and automation accelerate change across the software lifecycle.
Speed
Moving quickly allows for innovations to get into the hands of customers sooner and better adapt to changing markets. DevOps uses design approaches such as microservices and practices such as continuous delivery and integration to increase development velocity.
Rapid Delivery
Frequent delivery of new releases is a healthy metric of a software organization. The faster that new features, enhancements, and bug fixes can be released; the better you can respond to customer's needs.
Scale
One of the most difficult challenges in the delivery of software can be the operation of applications at scale. Large systems often require clustered hardware/software resources, real-time monitoring/alerting, and a commitment to cloud-friendly architectures.
Reliability
Practices such as continuous integration and continuous delivery contribute to the reliability of an application the way that infrastructure as code contributes to scale. By providing comprehensive test suites and ensuring that they are invoked on each commit, it’s possible to know that commits are both functional and safe.
Security
Rigorous testing and continuous integration, adoption of cloud platforms and infrastructure as code practices, along with multi-disciplinary teams that work together more closely combine to greatly improve application security. It allows DevOps organizations to move quickly while retaining control, preserving compliance, and data that can help show improvement. Many platforms allow you to go even further by also automating compliance policies and ensuring a granular permissions model using practices sometimes called “policy as code” which capture what best practice might be, and giving a template to audit against what has been deployed into production.
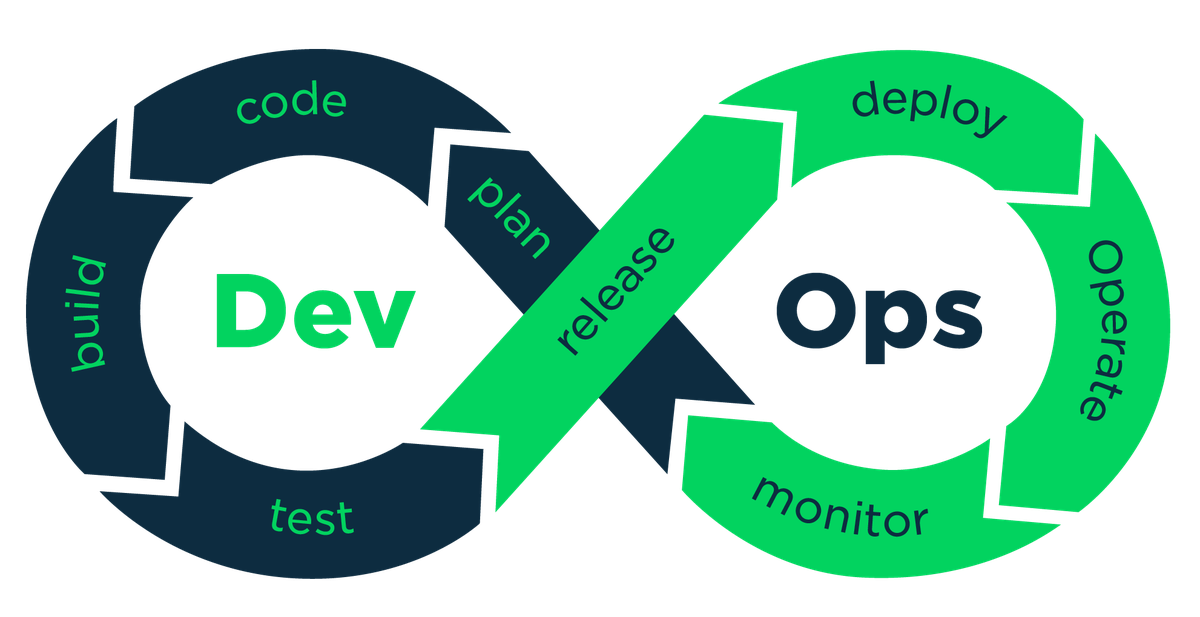
DevOps Principles and Practices
The guiding principle of DevOps might be described as: "Go Smaller."
How do organizations deepen their DevOps practices beyond initial adoption and apply them consistently in daily work? What principles and techniques allow teams to sustain speed, measure reliability, and manage change with confidence?
At its core, DevOps is about designing processes that make best practices the default. A useful way to frame this is the guiding principle of “go smaller.” Smaller changes reduce risk, tighten feedback loops, and make delivery easier to observe and control—an idea reinforced in both the DORA 2024 and 2025 reports, which show that high-performing teams consistently work in small batches and rely on disciplined, repeatable workflows. Frequent, incremental updates allow teams to detect issues earlier, respond faster, and improve quality while the context of a change is still fresh.
The same principle applies at the system level. Breaking large applications into smaller, independently operated services reduces coordination overhead and allows teams to scale, deploy, and recover components without forcing system-wide changes. This approach supports the broader DevOps goal of aligning delivery speed with operational stability—provided it is paired with automation, observability, and clear ownership.
Of course, these benefits are not free. Smaller changes and distributed systems increase operational complexity, placing greater demands on tooling, automation, and collaboration. DevOps practices exist to manage that complexity deliberately ensuring that as delivery accelerates, reliability, transparency, and control are strengthened rather than eroded.
What the Data Reinforces
Research from DORA 2024 and 2025 shows that high-performing organizations don't rely on isolated tools or practices. Instead they consistently invest in a small set of reinforcing fundamentals: automation that reduces toil, small and frequent changes, strong feedback loops, and platforms that make reliable delivery the default. These principles correlate strongly with better delivery performance and become more critical as AI and automation increase speed and risk.
Based on findings from 2024 and 2025 DORA Accelerate State of DevOps Reports.
Automate Everything
The good news is that the additional overhead and challenges that DevOps introduce can be addressed with tooling. For this reason, a core principle of DevOps is "automate everything". Many jobs within traditional operations require a great deal of manual labor and consume significant amounts of time. Examples include:
- testing of the software: unit, functional, and integration
- staging new changes and building new artifacts
- deploying the staged environment to live production use of the application and performing actions required to upgrade components (such as running database migrations)
All of these tasks can be automated through practices such as Continuous Integration / Continuous Deployment (CI/CD) for deployments, Infrastructure as Code (IaC) for automating environments, and observability systems to automate detection and response for various types of events.
After an initial investment to build CI/CD and supporting pipelines, the entire process of testing and upgrade can proceed automatically. This means that every time a developer commits a new source code change, a verified and tested update can be pushed to production, the deployment can be verified, and the upgrade rolled out with zero downtime. Mature pipelines at companies such as Amazon have been reported to push upgrades thousands of times per day.
Other practices, like Infrastructure as code and configuration management, can help to scale computing resources as demand spikes. Further, the use of monitoring and logging when combined with automated actions can help systems react to outages of part of the system without needing to take everything offline.
Taken as a whole, DevOps practices help to deliver better and more reliable code to their customers more often. In the remainder of this section, we will provide an overview of key practices and some of the tools that are used to implement them: microservices, monitoring, infrastructure as code (IaC), continuous integration (CI), and continuous delivery (CD).
Automation Checklist
- Build and test on every change
- Promote artifacts (don't rebuild)
- One-click/one-pipeline deploy
- Automated migrations with rollback plan
- Policy checks (security/compliance) in continuous integration
- Observability baked in logs, metrics, and traces
- Release gates based on telemetry, not vibes
Microservices
A microservice is an architectural model with an approach based on splitting up large, monolithic programs into small sets of services that communicate with one another. Each service is a standalone process that talks to other processes through an application programming interface (API).
Microservices are independently built around different business capabilities; meaning each service has a single purpose. They hasten the development of an application significantly, as they are designed, programmed, and tested individually. In contrast, a monolith supports an entire application in one service. Having a tightly coupled service can create bottlenecks that are hard to work around. As an example, consider a service that includes an interface to a database and a search interface both in the same application. If the database becomes bottlenecked, the only way to increase the performance of that one piece is to deploy a second instance with both search and database interfaces, despite no issues with the search code. In a microservice architecture, where the database and search interfaces are separate, the database component can be scaled without needing additional instances of search.
This idea can be taken one step further through the use of Functions as a Service (FaaS). FaaS systems allow for very small pieces of functionality to be exposed for consumption via a network. Complex applications mix and match the functionality of lower-level pieces in order to deliver complex functionality to users.
Monitoring
Monitoring is the real-time observation of the application's well-being. DevOps encourages organizations to integrate monitoring into every part of an application's operations. This allows for insight into performances, in addition to providing notification about failures (and why they may have occurred).
Operational data is valuable. It can be used to run analytics, drive decision making toward updates, show how users engage with parts of the system, and help in making decisions about what features should be developed or patches created. When utilizing a microservice architecture, monitoring (and event aggregation) becomes critical as you have multiple processes running in different environments you must keep track of. When working with systems that might span individual servers, understanding the big picture requires that you track and aggregate it.
Infrastructure as Code
Infrastructure as Code is the practice of using the same tools and methods leveraged for software development in the management of infrastructure. At a practical level, this means that application configuration will be kept in version control, analyzed, and tested using continuous integration pipelines. Developers and administrators are then able to leverage the configuration and application interfaces to interact with infrastructure programmatically.
This allows for resources to be deployed, updated, and managed without needing to manually configure them. When streamlined, it is possible to interact with infrastructure as though it were application source code. This allows for servers to be deployed quickly using standard templates, updated consistently, and duplicated efficiently. Infrastructure as code goes a long way toward solving the challenges of running applications at large scale.
DevOps Practices Work Together
Microservices, CI/CD, infrastructure as code, monitoring, and collaboration/review are not independent techniques. Each practice reduces risk introduced by the others: smaller services demand better observability, automation requires versioned infrastructure, and faster releases depend on strong feedback loops. DORA's research consistently shows delivery performance improves when these practices are adopted together rather than isolation.
Continuous Integration
Continuous integration takes the automation of tests to the next level. It integrates suites of tests into "pipelines" that can be executed when developers merge and commit their code to a central repository. Such pipelines allow for the state of a software project to be monitored continuously, with the goal of finding and addressing bugs more quickly so that software can be validated and released more frequently. Continuous integration leverages automation applications like Jenkins or Travis-CI to automatically detect new source code changes, and immediately run tests on the new code.
Continuous Delivery
Continuous delivery couples the testing to pipelines which can automatically build and prepare the software for deployment to a staging or production environment. When continuous delivery functions as intended, developers and operations will have software builds that have gone through a rigorous testing process and is ready for deployment. Using such systems, companies such as Etsy, have reported being able to update their production environments fifty times per day (or more). With a strong CI/CD pipeline, you tackle traditional software releases by deploying frequent confident changes, knowing that each release has undergone an extensive quality testing cycle. CI's goal is to provide confidence in the functionality of the program through testing, while CD is handling the deployment of the application into production.
Communication and Collaboration
By converging development and operations, aggressively adopting automation, leveraging infrastructure platforms, continuous integration/development, and monitoring; it becomes essential that all members of a team communicate. DevOps tooling allows for messaging to come together from multiple streams into common platforms such as chat, project tracking systems, and wikis. Using such tools and setting expectations about how groups should communicate helps developers, operations, and other teams (such as marketing and sales) align more closely and reach organizational goals.
Develop With Confidence
DevOps practices follow a natural progression:
- Small changes: microservices, CI
- Repeatable delivery: CI/CD, IaC
- Operational feedback: monitoring
- Shared ownership: collaboration
Together, they turn change from a risky event into a routine operation.
Case Studies
DevOps proves its value most clearly when systems are under real pressure. The following case studies from Amazon, Netflix, and Etsy show how DevOps principles are applied to solve different classes of problems: operating at massive scale, surviving constant failure, and restoring trust in rapid change.
Taken together, they demonstrate that DevOps is not a single recipe, but a disciplined way of strengthening foundations so speed, reliability, and confidence can grow together.
Amazon
One of the initial challenges that pushed Amazon towards the adoption of DevOps was how to determine how much server space might be needed at any given time, without wasting the excess. During most of the year, Amazon would leave as much as 40% of their total server capacities unused; with far too much processing compute time being wasted on their physical servers.
To consolidate server workload, Amazon made the decision to shift from physical to virtual servers; and in the process, pioneered many Infrastructure as Code Practices. They then built sophisticated systems to allow for configuration descriptions and complex software stacks to be automatically deployed on top of the resulting environments. The resulting systems have made Amazon much more efficient. On average, Amazon reports that they are able to deploy new versions of their software services every 11.7 seconds. Once the systems were working well internally, Amazon chose to expose many of them for use outside of the company and created a significant value stream contributes more than $100 billion to company revenues each year. Collectively, Amazon Web Services (AWS), have become the major option for other companies wishing to use "public cloud."
In recent years, Amazon has continued to evolve internal Devops driven platforms to address new classes of workload and operational complexity. Amazon Web Services has expanded beyond basic compute and storage to include managed container platforms (Amazon EKS), serverless execution (AWS Lambda), and AI-native infrastructure (Amazon Sagemaker). All Amazon services build on the same set of core assumptions: infrastructure is programmable, deployments are automated, and operational state is observable by default. Amazon has also invested heavily in supply-chain security, artifact signing, and workload isolation through initiatives like AWS Nitro and signed AMIs, reflecting a broader industry shift toward verifiable policy-driven delivery pipelines. These continued investments underscore that Amazon’s DevOps journey was not a one-time transformation, but an ongoing process of reinforcing the same foundations as scale, regulation, and AI-driven workloads place new demands on the platform.
Constraint
Amazon's growth turned software delivery into a scaling problem: thousands of teams, constant change, and zero tolerance for downtime.
What DevOps Enabled
- Ownership shifted to "you build it, you run it"
- Small independent services replaced centralized releases
- Automation and internal platforms made safe change routine
Why It Worked
DevOps aligned delivery speed with operational accountability, which transformed deployment from a risk into a highly repeatable process.
- Frequent, low-risk releases
- Rapid recovery from failure
- Delivery treated as infrastructure, not heroics
Amazon Web Services
With a robust service-oriented strategy has come strong profits. AWS is Amazon's most profitable product. Not only is it used by Amazon to efficiently sell their merchandise and that of their partners, but they also host the operations of tens of thousands of other organizations. Examples of AWS DevOps services include:
Amazon SageMaker
Amazon Sagemaker provides systems and services to train, deploy, and monitor AI models. This allows for Amazon and outside users to leverage AI for a large number of use-cases including optimizing operations, generative AI, and more.
By applying DevOps discipline to machine learning workflows, SageMaker reflects a broader industry shift highlighted in recent DORA research: AI success depends less on models themselves and more on the delivery systems that support them. In this way, SageMaker represents a natural extension of Amazon's DevOps foundations into AI-driven systems.
AWS Developer Tools
AWS Developer Tools are a set if services to help develop and deploy code using CI/CD principles. They provide systems for storing and versioning of source code, automatically creating builds, invoking tests, and deploying application artifacts to AWS infrastructure. Related services include AWS CodePipeline, AWS CodeBuild, AWS CodeDelopy, AWSCodeStar.
An example use for AWS CodeDeploy is allowing developers to create blue/green deployments that help minimize downtime during updates. A Blue/green deployment works by having a new version of the application staged alongside the old version, testing the new version before traffic is routed to it, and mapping the new routes upon successful completion of the tests. Using strategies like Blue/Green deployment can allow for updates with near-zero downtime.
AWS Cloud Storage
AWS Cloud Storage is a service that provides affordable and scalable storage. Among the most popular of the AWS services, it is used by many companies as a reliable way to warehouse huge amounts of data. Alongside data storage, AWS provides distributed computing systems such as Amazon EMR, which can be used to process the data using Machine Learning, distributed analytics, and large-scale ETL.
Among the companies using Amazon's analytics services is GE Healthcare, which detects critical conditions faster using deep learning on AWS. GE created a database (GE Health Cloud) on top of Amazon's virtualization system (Elastic Compute Cloud or EC2), capable of processing more than a petabyte of medical imaging data stored inside of Amazon Simple Storage Service (S3). The distributed nature of the system and high throughput allows for GE to quickly run simulations and queries in near real-time.

Dive Deeper: Building Secure and Compliant Medical Systems
Want to see what DevOps looks like when it meets regulated clinical reality? These GE-on-AWS videos show how repeatable automation, reliable infrastructure, and observable operations turn “moving to the cloud” into a delivery system you can trust. Especially when imaging data, uptime, and compliance are non-negotiable.

Netflix
Netflix started its DevOps journey for the reason many do: because of catastrophe. Badly hurt by a major outage in their physical database infrastructure in 2008, which halted all service to customers for three days, Netflix decided to adopt cloud computing techniques and architect their applications as robust systems of micoservices. In taking this approach, Netflix designed services to tolerate failures and isolate blast radius.
Taking resiliency to the extreme, Netflix has pioneered approaches called "Chaos engineering" wherein they actively introduce failures in specific components to ensure that the system as a whole remains operational. This has led to a a thriving DevOps-based culture utilizing AWS, test automation, and continuous deployment. Netflix prides themselves on being able to test, package, and deploy much of their software stack within minutes without disrupting the streaming services that must be running all day, every day for tens of millions of subscribers.
AWS and Spinnaker
Netflix makes extensive use of Infrastructure as Code, cloud computing capability, and continuous integration/deployment.
Netflix learned the hard way that vertical scaling of computer resources was not a proficient way of hosting a database. When their database corrupted in 2008, they were forced to rebuild the entire system from the ground up. They further learned that increasing or decreasing computing power to one machine is a very limited way to grow a system. From this, they aggressively adopted a horizontal scaling model. In horizontal scaling, improved elasticity of the system is gained by adding additional instances on new infrastructure, either physical or virtual, rather than more RAM or CPU to a single machine.
Netflix uses AWS for nearly all its computing and storage needs including databases, analytics, video encoding, recommender engines, and hundreds of other functions that require over 100,000 server instances from AWS. Netflix logs all of its information data for monitoring and analytics using Amazon Kinesis Streams, a service that centralizes the data of the application into a pipeline that can be consumed by other monitoring applications.
When Netflix was initially developing its streaming platform, a massive issue arose; "How can they maintain the platform without having the servers go down for maintenance?" To solve this problem, Netflix and a group of developers started a project called Spinnaker. An open-source tool that implements continuous deployment, Spinnaker has become one of the most popular platforms for automating the roll-out and update of software builds.

Constraint
Operating a global streaming platform meant failures were inevitable, but outages were unacceptable.
What DevOps Enabled
- Designed explicitly for failure
- Invested early in observability and resilience tooling
- Treated chaos as a validation mechanism, not a threat
Why It Worked
DevOps practices made failure visible, contained, and recoverable so innovation could continue without fragility.
- High availability at massive scale
- Fast experimentation without systemic risk
- Operational confidence built into the platform

Dive Deeper: Resilience You Can Ship
These two talks connect the dots between Netflix’s cloud migration and the delivery machinery that made it sustainable. Watch them to see how DevOps becomes a system: reliability engineered into architecture, and repeatability enforced through pipelines—so teams can move fast without making every release a high-stakes event.


Etsy
Before adopting DevOps practices, Etsy faced a familiar problem for fast-growing platforms: a large monolithic application, infrequent releases, and a growing fear of deployment. Changes were bundled into large updates, coordination costs were high, and teams lacked confidence that releasing new features wouldn’t disrupt the marketplace. The result wasn’t just slower delivery—it was organizational friction, with developers and operations teams operating defensively rather than collaboratively.
Etsy’s DevOps transformation focused on reducing the cost of change. By investing heavily in continuous integration, automated testing, and deployment pipelines, Etsy shifted from a mindset of “release avoidance” to one of continuous delivery. Deployments became smaller, more frequent, and easier to reason about, which allowed teams to experiment, learn from real user behavior, and respond to issues quickly without system-wide downtime. Just as importantly, these changes improved internal trust: engineers could see the impact of their work in production and had the tools to detect and correct problems early.
Monitoring played a central role in this shift. Systems like Kale allowed Etsy to treat deployments as observable events rather than blind leaps of faith. Every release was measured, validated, and rolled out with confidence that anomalies would be detected before affecting users. Over time, this feedback loop enabled Etsy to sustain dramatic growth while deploying dozens of times per day demonstrating that DevOps success is as much about visibility and culture as it is about automation. Concurrent with this transition was huge growth of the platform as it was able to better meet customer needs without downtime.
Jenkins and Kale
While a competitor to Amazon in many ways, Etsy is among many large companies that use AWS for their operations. Like Netflix, Etsy leverages many AWS services to provide a stable and robust platform.
- As noted above, Etsy is able to deploy code between fifty and one-hundred times per day. They do this through the use of CI/CD pipelines run on top of Jenkins capable of executing more than 14,000 test suites each day.
- To track the many different services required to operate the platform, Etsy built Kale, a monitoring system that is utilized to detect anomaly patterns within the infrastructure operations data. Kale is used to monitor every deployment that Etsy performs while making sure the application is stable and healthy before making it available to users.

Constraint
Rapid feature development conflicted with site stability and team burnout.
What DevOps Enabled
- Continuous delivery as the default
- Small changes released frequently
- Monitoring and feedback embedded in daily work
Why It Worked
DevOps reduced the cost of change making quality, speed, and sustainability compatible goals.
- Dozens of deploys per day
- Lower failure impact
- Healthier engineering culture
Implementing DevOps
Tools to get you started.
Implementing DevOps with Open Source
The Open Source ecosystem provides a comprehensive suite of tools that can be used to implement all aspects of DevOps. Important tools include:
Git
Git is a distributed content versioning system that has become the most popular software tool for tracking and managing source code. Additional platforms, sometimes called code forges, can be used to facilitate collaboration between developers working on software. The most popular hosted forges include GitHub and GitLab.
Terraform
Terraform is an Infrastructure as Code (IaC) tool focused on provisioning (rather than configuration). It allows teams to declaratively define cloud and on-prem resources (networks, compute, storage, IAM) using a consistent workflow. Terraform complements tools like Ansible by managing what infrastructure exists, while configuration tools manage how it is configured.
Ansible
Ansible is an Infrastructure as code (IaC) tool that allows for the automating of the provisioning and deployment process for infrastructure. Automation is configured as a readable description of state in yaml called playbooks. Provisioning tools read the description of state and then generate sets of instructions that will create an environment that matches.
OpenTelemetry
OpenTelemetry is a vendor-neutral standard for collecting and exporting telemetry data—metrics, logs, and traces. It provides a consistent instrumentation framework across languages and platforms, enabling observability to be built into systems by default rather than added later.
Docker
Docker is an end-to-end platform for building, sharing and running container-based applications. Used in environments as diverse as a developer's desktop to the cloud, Docker allows for the same build artifact to be leveraged at every stage of an application's lifecycle.
Kubernetes
Kubernetes is an open-source orchestration system for automating deployment, scaling, and management of containerized applications. Increasingly, Kubernetes (and the further systems that build on top of it) has become the core component of DevOps infrastructure. Kubernetes works closely with container technologies such as Docker. While Docker handles the execution and packaging, Kubernetes automates the processes of deploying Docker-based software across broad clusters of systems.
Helm
Helm is a package manager for Kubernetes that simplifies the deployment and lifecycle management of complex applications. It allows teams to define reusable, versioned application templates (“charts”) that encode best practices for configuration, upgrades, and rollback—reducing operational friction as systems scale.
Prometheus
Prometheus is an open-source monitoring and alerting system designed for dynamic, distributed environments. It collects metrics from services and infrastructure, enabling teams to observe system health, define alerts, and support data-driven operational decisions. Prometheus has become a cornerstone of modern observability stacks.
Grafana
Grafana is a visualization and analytics platform commonly used alongside Prometheus. It provides dashboards and alerts that help teams understand system behavior, performance trends, and operational risk. Together, Prometheus and Grafana turn raw telemetry into actionable insight.
From Chaos to Craft
Software really is eating the world—but that hunger has consequences. As software has moved from supporting businesses to being the business, failure has become more expensive, change more frequent, and complexity unavoidable. The story of DevOps is the industry’s response to that reality: a recognition that how we build and operate software matters as much as what the software does.
Across this article, a consistent pattern emerges. The practices that define DevOps are not about chasing speed for its own sake, nor about adopting the latest tools. They are about strengthening foundations: making change smaller, feedback faster, ownership clearer, and outcomes visible. When delivery becomes a system rather than an event, organizations stop relying on heroics and start relying on design.
The case studies make this concrete. Amazon shows what happens when delivery is treated as infrastructure and scaled deliberately. Netflix demonstrates how resilience can be engineered when failure is assumed rather than feared. Etsy illustrates how restoring confidence in change can unlock both velocity and healthier teams. Different industries and different pressures, but the same lesson: DevOps works when it aligns architecture, process, and accountability around reliable change.
What makes this moment different from DevOps’ early days is accessibility. The tooling required to build disciplined delivery systems — versioned intent, automated provisioning, consistent runtimes, orchestration, and observability — is now broadly available, largely open source, and well understood. The challenge is no longer whether DevOps is possible, but whether organizations are willing to apply it deliberately, invest in fundamentals, and treat delivery as a product in its own right.
DevOps was never a revolution in tools. It was a revolution in responsibility. And in a world where software continues to eat everything in sight, that responsibility has only grown more important.






Comments
Loading
No results found