What Is Data Science?
Revealing the insights within the data that impacts our lives.
Our world is awash in data. Every action that takes place in a company, with customers and in the marketplace creates it. When we buy products, users interact with services, and colleagues collaborate, information is captured. Each time we visit the doctor, drive our cars, get on an airplane, or take a photo we produce more.
In the right hands, data can drive new insights and powerfully informed decisions. When combined with advances in artificial intelligence and machine learning, data can be transformational; and this makes it valuable.
Because of the value posed by data, an entirely new set of disciplines has emerged in order to capture, store, and work with the modern deluge. Collectively grouped under the label of "Data Science," this set of disciplines and its practitioners are positioned to help use information in new, exciting, and impactful ways such as:
- aiding doctors in the diagnosis of disease
- decreasing the time required to safely transition new medications to market
- streamlining the transportation system so we can move people more quickly and efficiently
- modeling disease outbreaks and helping to contain dangerous pathogens
Yet, for all of its importance and promise, Data Science is a poorly defined and misunderstood thing. In this article, we'll attempt to clear some of the fog. We will look at:
- how an increasing volume and diversity of data drives the need for Data Science capabilities
- what Data Science is and the steps required to build a data-driven organization so you can use its tools effectively
- the roles within the Data Science landscape and how they work together
- why organizations need Data Science in order to stay relevant and competitive
The Modern Information Flood
The modern world generates a lot of information; an enormous, ever increasing amount of information from a huge variety of sources.
According to Gil Press of Forbes: In 2005, all data produced from all sources was about 0.1 zettabytes (100,000 petabytes or 100 exabytes) of data. By 2010, this had grown to 1.2 zettabytes of data. Today (in 2020), we produce round 44 zettabytes of data, and by 2025 it is projected that we will produce 180 zettabyes or more each year.
It is difficult to put into context just how much information that is, but it's helpful to try:
- it includes every written word, image, and video that is captured across the entirety of social media
- satellite imagery that scans nearly every inch of the earth and is broadcast back to the surface in (near) real time
- the entire genetic sequences of millions of people
and many other sources. It encompasses the lives and existence of a growing population of seven billion human beings and counting.

Connection and Connectivity
While much of the information has (more or less) always been available, technological advances have greatly changed how we acquire and store it.
The first of these advances has been the connection of people throughout the world. Through networks such as the Internet and services such as social media, there are more ways for people to interact than at any other point in human history. Search services such as Google and Bing, social media such as Facebook and Twitter, messaging applications like SnapChat, online video services such as YouTube and Vimeo, transportation services such as Uber and Lyft, financial services such as Venmo, and many others are used by more than half of the human family.
The second development has been the rise of mobile phones and other Internet connected devices. Starting with the iPhone in 2007, nearly every adult has access to a powerful and portable computing device that is capable of tracking location and acquiring personal metrics such as activity or heart rate. To say nothing of its ability to collect audio, imagery, and video data. When combined with the computing advances available from the "Cloud", mobile has made it possible to generate an nigh-infinite stream of data about the most personal information.

And There's More ...
Data comes not only from people and mobile devices, there is an entire universe of additional information produced by sensors and Internet of Things (IoT) devices. These include satellites, weather and scientific monitoring systems, automated transport systems such as drones and self-driving cars, and many other sources.
All of this data encodes detail about our world and the ways in which we interact with it. It represents an inexhaustible stream of potential insight and action, an analytic pot of gold.
What is Data Science?
Which is where Data Science enters the picture. Data Science is the art of turning data into action. It's the set of tools and techniques we use to mine and refine the crude information into insight and intelligence.
Data Scientists, Engineers, and Analysts produce data products which are in turn used to support decision making. They are intended to answer questions such as: "Where should I invest my ad dollars to increase profit? How can I improve compliance while reducing costs? How can I improve communication and collaboration to better build products?"
As these questions become better understood, the data products built to supply answers take many forms, such as:
- recommendation engines capable of suggesting movies, books, articles, or other types of content based on a person's interests and needs
- forecasting systems which attempt to predict the weather, fluctuations in the stock market or other financial markets
- machine learning models that are able to help locate and take action on variations in industrial processes
- diagnostic engines capable of helping to automate the diagnosis of disease, ensure that the highest-risk patients receive prompt treatment, and safeguard public health by monitoring disease outbreaks
- customer management systems which can improve a company's impact by helping to target advertising, improve interactions, and personalize products
Almost anything can potentially become a data product, meaning there is a near-infinite number of uses-cases. As a result, Data Science team have an enormous scope of responsibility. Additionally, because data products are built from many moving parts involving the entirety of the organization, they require investments in software, data infrastructure, operations, and teams.
No company becomes a "Data Science", "Machine Learning", or "Artificial Intelligence" company overnight. Strictly speaking, "Data Science" isn't really practiced by individuals.
Building Data Driven Organizations
Rather, it's an endeavor realized by teams, organizations, and communities. This means that to take advantage of its potential, the practice of Data Science requires a data-driven organization.
Building such organizations is a gradual process that moves through a series of phases that can be organized into a hierarchy or pyramid . Before you can move to the more sophisticated types of analytics available at the higher levels (such as being able to leverage artificial intelligence and machine learning), you first have to build the systems and processes of the lower levels.

There are generally five phases on the journey to Data Science actualization (artificial intelligence):
- data collection
- mastering data flow
- exploration and transformation
- aggregation, enrichment, and labeling
- experimentation and optimization
- machine learning and AI
Collect
At the bottom of the pyramid is the most fundamental of all data needs: collection. Are there systems in place that capture important events and transactions? For example, do you have a website? Is the website connected to an analytics solution? Do you track customer interactions using a CRM tool? Is there a marketing automation solution used in the organization? Do you track how the work is fulfilled? Do you solicit customer feedback about their experience while interacting with your organization?
While the systems required to collect this data may be a separate program (a "data silo"), for an organization to become more sophisticated it's required information to improve operations.
Mastering Data Flow
After the systems are present to collect data, the next challenge is to begin to integrate it. You need to ensure that information gets to the right place at the right time and is combined with other pieces to provide more context. Sometimes referred to as "data flow," this is when you begin to assemble pieces of information from the silos into something cohesive. For example, is there a complete profile of a customer? Are the leads in the CRM also registered with the marketing automation software? Is it possible to track the type of content the user visits on the website and which emails they have opened? Can we track which purchases have been made and whether invoices have been paid? Do we have feedback on their experience and information about what actions were made to follow-up?
While it may seem foundational, mastering data flow is difficult. It often requires the use of extract/transform/load (ETL) pipelines to combine information, consideration about where and how information will be stored, attention to when it will be processed and updated, and thoughts about who will be able to access it (data governance).
Explore/Transform
Once data is accessible, then you can begin to explore and transform it to gain a basic understanding of its structure and content. This is when you discover issues and problems with pipelines, incomplete collection due to poor business processes, mismatched records due to inconsistent keys, and a whole host of unforeseen issues. Next, you clean the data. You remove incorrect data points and dig into anomalies. You determine why data is inaccurate and where things went wrong during collection. After discovering issues and problems, you go back to the earlier levels and adjust the collection system and ETL to ensure that your information is accurate.
This is the point at which many data strategies begin to bear fruit. It provides an opportunity to shore-up the base of your pyramid and begin to trust your organization's data as a reliable source of intelligence.
Aggregate, Enrich, and Label
Clean, reliable, and verified intelligence is the foundation of insight, and this is the stage when you can begin to apply analytics. With the entirety of your organization's data available, it's possible to define key performance indicators (KPI) metrics, aggregate information and track trends in seasonality, or quantify the effect of events or campaigns. You can start to ask simple questions and have confidence in the answers. Further, you can start to look at datasets provided by external groups -- such as government or other public institutions -- and enrich the resources available to you internally.
This is also the stage where you begin to think about how you might apply machine learning techniques or artificial intelligence. It's where you start to engage in "feature engineering" and think about new perspectives on your data that are more than the sums of their parts.
Experiment, Learn, and Optimize
Using the insights you've gained from analytics and the expanded picture afforded by enrichment, you are in position to take action. Using enhanced customer segments, you might choose to personalize content for a user based on previous interactions. Or, you might choose begin to incorporate recommendation engines to help drive users towards content or information more relevant based on their needs.
At this phase, you are ready to build and deploy machine learning systems alongside your infrastructure and measure their impact. You can experiment with different types of features and interactions, and iteratively evolve toward successful processes that help your organization.
What Makes Data Science Different?
Stop me if you're heard this one. What do you call a statistician from San Francisco?
At this point, you are probably saying, "This sounds all well and good, but isn't new. What makes Data Science different from other analytic methods and strategies?"
Explore, Hypothesize, Experiment, and Back Again
First, Data Science takes advantage of advances in processing, parallel computing, and statistical modeling to work with ever-larger datasets in more sophisticated ways.
This opens up new forms of analysis. Rather than focus on purely deductive (hypothesis-based) reasoning, for example, a data scientist might switch between deductive and inductive (pattern-based) reasoning to formally assess one hypothesis and then use exploratory data analysis to generate completely new ones. Put another way, Data Science encourages a workflow where you explore the data, hypothesize about underlying contributions, create experiments to test your hypotheses, and and then refine your understanding of the data based on the results of those experiments. It's highly iterative and adapts in near real-time.
While this may sound simple, consider how it might play out in the context of an advertising campaign:
- You draw upon existing customer segments and interaction to understand how uses have previously responded to marketing messages and value. In the process, you may refine your segments based on approaches such as click-stream analysis, which can provide information about where users failed to engage with previous campaigns.
- From that historical data, you craft pitches and sales funnels to engage users in the new campaign. Built into the sales process is a set of alternatives which allow you to explore alternative hypotheses and determine which message will be the most effective.
- When launched, sophisticated software platforms that incorporate machine learning allow you to monitor how your campaign unfolds. Through practices such as AB testing, you can watch how certain messages result in higher conversions and switch other segments to those messages as soon as they become obvious. Or, you might allow for the machine learning algorithm to do that for you.
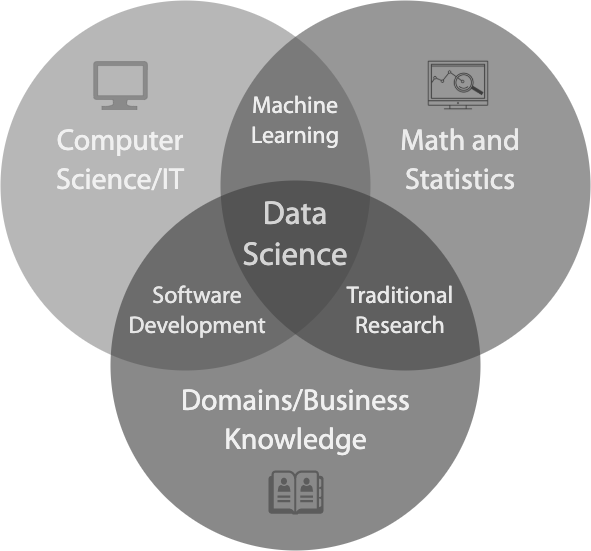
The Best of Every World
Second, using Data Science tools and approaches allows for organizations to quickly and iteratively learn from data. Data Science exists at the intersection of a powerful set of disciplines: computer science, math, statistics, and domain expertise. It is able to draw the best practices from each and endeavors to put them to work at enormous scale.
Machine learning models, for example, allow for insights to be deployed, processes to highly personalized, and the automation of entire organizations. That is a huge competitive advantage, and it is only the beginning. Organizations that leverage Data Science tools such as Natural Language Processing (NLP) or computer vision are able to access sources of information beyond what is available to their competitors. Consider how NLP can aid in the analysis of a survey, for example.
The best insights to process improvements are frequently hidden within the responses to free-form questions such as, "What can we do to improve?" or "What did we do well?" Such questions allow customers to share their feelings without boxing them into a set of pre-determined categories.
Analyzing such data is difficult, however. It requires an analyst or specialist to review every survey, identify the trends, and aggregate the results. That process becomes untenable when you have more than a few hundred (or thousand) responses.
Using NLP, however, you can review all of the data, even if you have tens of thousands or millions of responses. An NLP process called "named entity recognition" can help you determine what is being talked about and locate relevant samples. You can then use "sentiment analysis" to help you understand how people feel about certain topics and dig deeper. You will likely still have an expert review some of the data, but that time can be spent much more efficiently after you have already determined what people are talking about and the general sentiment.
Using Data Science approaches, something that was previously inconceivable is suddenly feasible, efficient, and achievable.
Building Data Science Capabilities
The effective practice of Data Science is something built over time. It is a rich discipline at the border of software development, business and domain knowledge, operations and engineering, and inquiry. It requires you to collect data, structure and update it, seek understanding through exploration, and enrich the raw information before you are able to utilize it in machine learning and artificial intelligence applications. Because of this, building capability is about nurturing teams and cultures.
Most of the time, it's impossible to find "unicorns," those rare individuals who have skills across all of the required domains to guide a project through all the phases required for success. Instead, it's better to create blended teams that are able to work together. Broadly speaking, there are four roles within Data Science -- software development, business analysts, data engineers, and data scientists -- all of which play an important part in a successful data-driven organization.
Software engineers automate processes, create interfaces to make information available, and build entirely new systems.
Business analysts bring domain knowledge and understanding of how data insights fit into the larger picture of an organization's mission.
Data engineers have deep understanding about the sources of information in an organization. They create the systems required to transform data into intelligence. Working with data scientists, software engineers, and business analysts, they also create the infrastructure to transform insight into action.
Data scientists help organizations ask important questions using data. They dive deep into the data to understand how specific variables contribute to the overall big picture.
While each of the roles unlocks new capabilities for the other, you can achieve value at every level of the pyramid.
- Using software developers to create applications that capture information about customer engagement can be very valuable, even if you don't have data engineers to combine it with CRM data.
- Creating a unified customer portfolio through ETL pipelines built by data engineers clarifies relationships and interactions, even if the data isn't being mined in aggregate by business analysts or data scientists.
- Analytics and dashboards built by data analysts using business intelligence tools provides strategic insight, even if you aren't creating machine learning systems to take immediate action.
Data Science Benefits
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
--- Zen of Python
While we've seen many implied benefits of Data Science, is is often best to explicit: Data Science tools, processes, and capabilities are transformative and will produce the future-leaders of every industry. It empowers better decisions, allows for more effective customer and faster response to the market, and provides ways to test decisions and dynamically adapt to responses.
Empower Better Decisions
When using Data Science techniques, executives and team leaders can base their decisions on a cohesive view of their organization's experience as informed by their data. Analytic and machine learning models built on top of that bedrock provide a stable foundation for informed, accurate, and efficient decision making.
Fast Response to Market
Through the use of data pipelines and adaptive models, organizations can leverage machine learning to quickly respond to changes in the market, trial new systems to engage their customers, and modify processes which are not working as intended.
Decision Testing
After an organization has built the infrastructure required for Data Science, it becomes possible to test the impact of decisions before rolling them out to the organization as a whole. This allows for confidence that a tested and tried solution will be the one that is finally used.
Conclusion
Our world is swimming in information, through the interconnection of society by the Internet and mobile we have created the ability to empirically describe our world in entirely new ways. Because that pipeline of information elucidates our shared reality, it is an extremely valuable resource. Data Science is about turning crude data into something useful so that we can gain insight and make better decisions as individuals, organizations, and a human family.
We put Data Science to work by building data products, a highly varied set of systems intended to help us answer specific questions. Building such products requires a diverse team -- software developers, business analysts, data engineers, and data scientists -- working together collaboratively. It also requires investment in the capabilities of an organization to collect; manage data flow; explore and transform; aggregate, enrich, and label; and experiment, learn, and optimize.
The potential for what Data Science can achieve is near limitless, it all comes down to having and using the right information. Because of this, the benefits of such investment is enormous and will produce the future leaders in nearly every industry; allowing us to do things that were previously unimaginable.
Comments
Loading
No results found